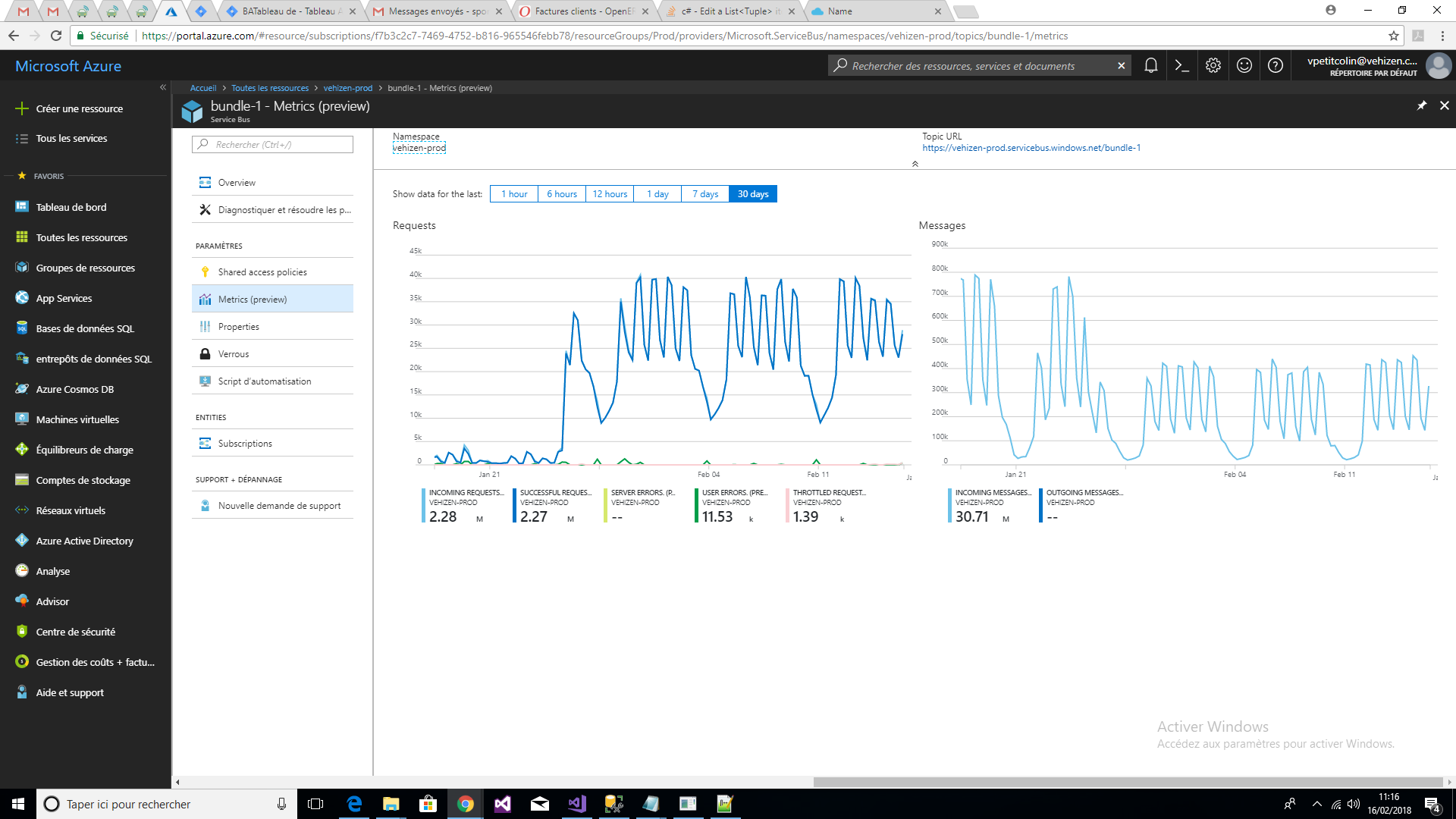
Since I switched to the Round Robin strategy 3 weeks ago (I also updated the NServiceBus.Azure.Translation.WindowsAzureServiceBus package from 7.2.9 to 7.2.11 in order to benefit of the patch for the RoundRobin present in version 7.2.10) and that I use two ASB namespaces instead of one, the number of requests on the topic bundle-1 has been multiplied by 10 while the number of incoming and outgoing messages has been divided by 2 (split between the two ASB spaces).
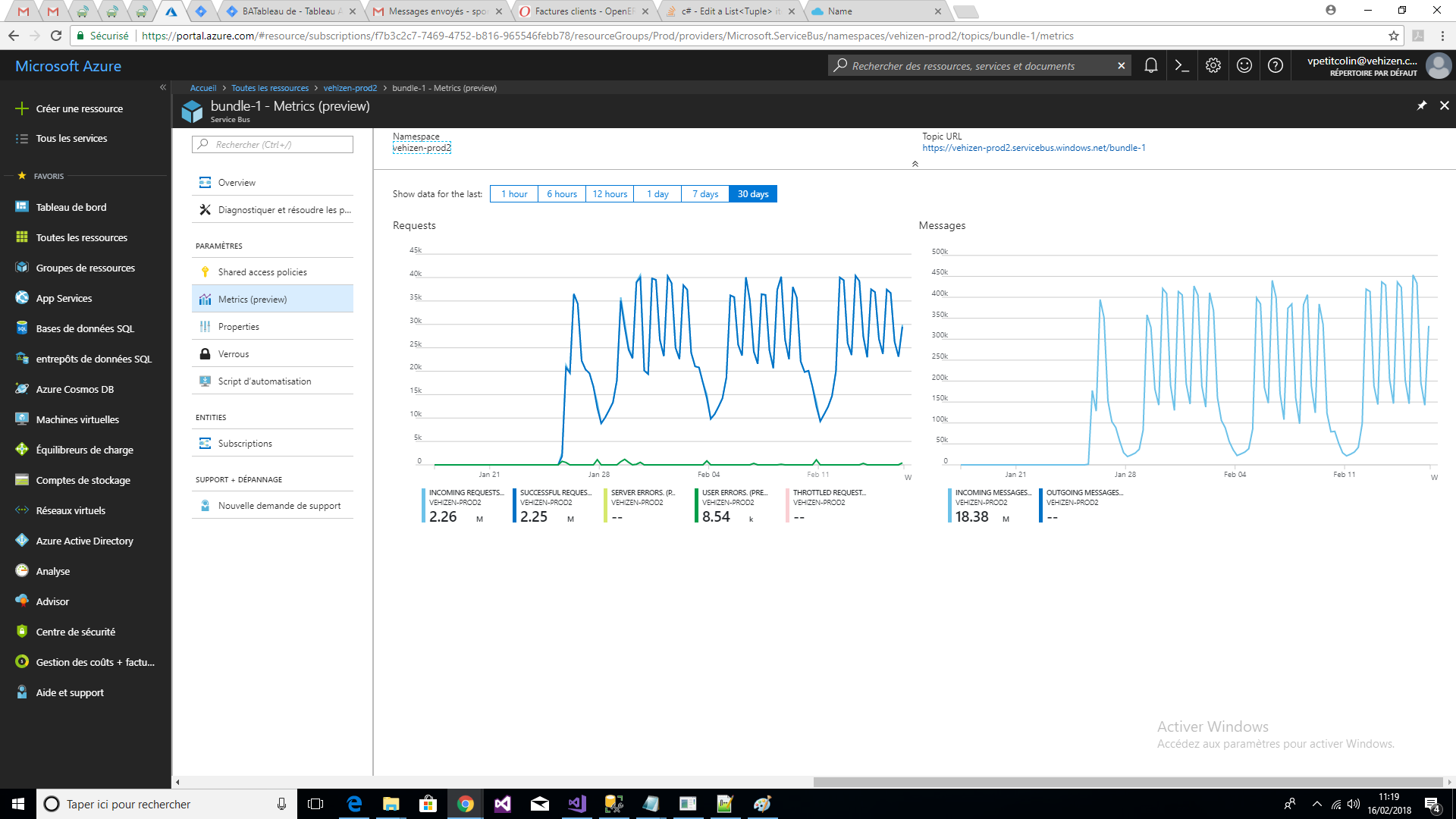
Here are the topics metrics on bundle-1 topics in ASB1 and ASB2 where you can see the differences after applying the RoundRobin strategy:
How to explain this impressive increase in requests? Only a problem related to RoundRobin uncached startegy?
This number of requests appears to impact the performance of ASB namespaces. for example, I have the sub-queue transfer message of the queue that increases during traffic peaks. Is there a way to overcome this problem?
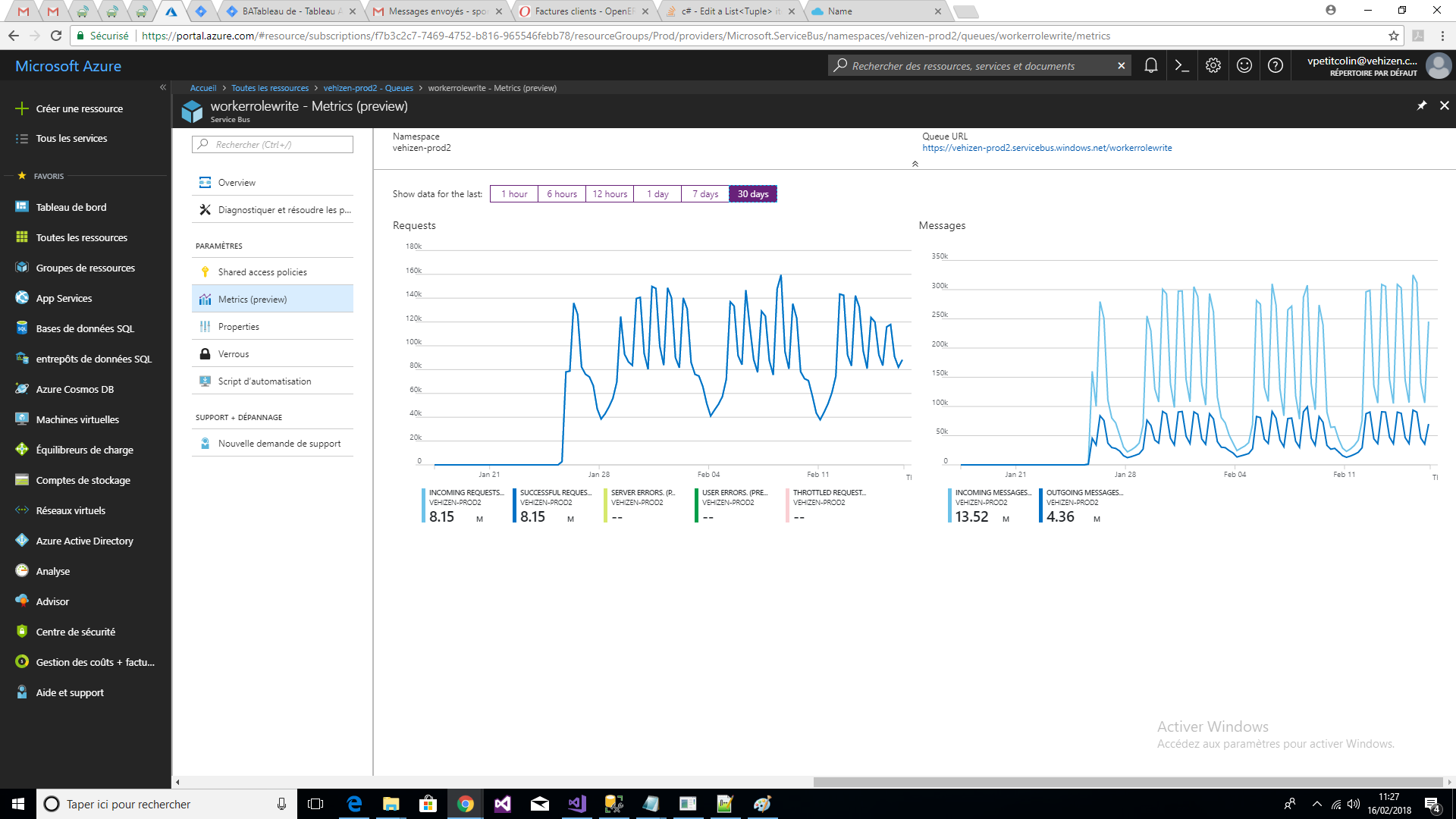
Conversely, as shown in the images below, the number of requests on the queues seems to have been divided by 10 (the possible cache problem would only concern the topics?) And the number of messages is well shared on the queues.
At first sight it looks like the requests have moved from ‘send’ to ‘publish’, you didn’t by accident change some of your logic to do publish instead of send?