Valid question. The answer is because of this database diagram. Text continues below…
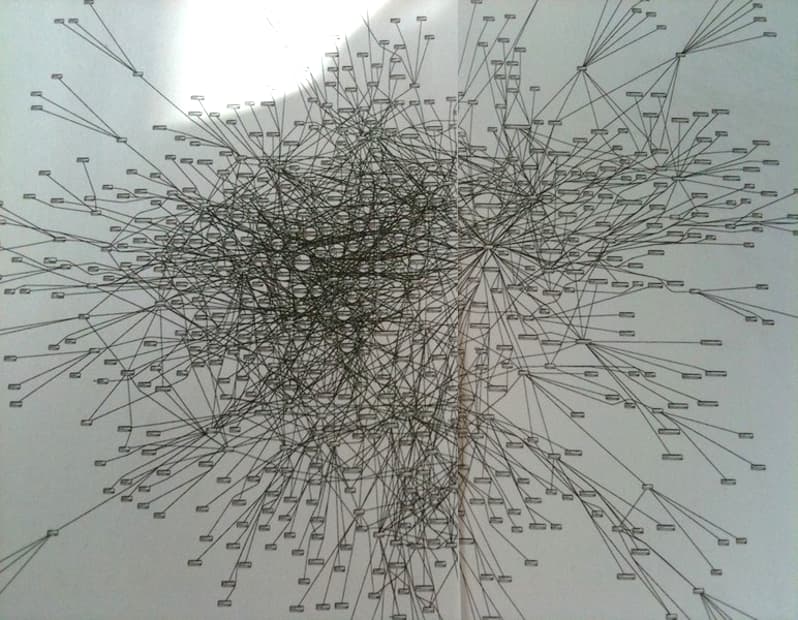
This is a database diagram I was once introduced to and had to work with. And it’s not even all of it, the actual thing was even bigger. The hardest part about a database like this is that there is an insane amount of hidden coupling. This means you can’t just change some code or feature, without potentially breaking a whole bunch of stuff you didn’t even know relied on it. As a result, I’ve been on numerous projects that had a very large test team that ran through hundreds of scenarios to make sure we didn’t break anything. But we still did, because it was hidden coupling and we broke something without knowing. So the test suites were extended with even more tests. Until a point where testing the system took longer than actually developing the feature. Which resulted in automated user interface tests. And then those became so complex, that you’d basically had to write tests for the tests, etc, etc, etc.
There’s no software without coupling at all, because that would mean things wouldn’t work together. But it’s possible to minimize the coupling as much as possible. That’s why Mauro and I created those presentations, to try and minimize the coupling. And it’s why we as Particular Software think you should temporally decouple bigger, logical services using event-driven architecture. And as a result build NServiceBus ![]()
Does that answer your question?