I’ve watched Dennis van der Stelt’s Autonomous microservices don’t share data seminar and he said that when you share data you lose authority and autonomy of that data. I can’t quite wrap my head around why this is bad. He gave an example about if the data is wrong you’ll have distributed wrong data and you won’t know who has it. Yes this is a possibility but other than this example I can’t quite understand why sharing data is bad. I’d be glad if anyone can share their opinion.
Welcome to the Particular discussion group, @deastr.
I discuss the topic of ownership in my “All our aggregates are wrong” presentation, where I provide different examples of why that can lead to issues.
Let me know if that helps.
Thank you. I’ve watched your presentation (and many others) and I also red your blog as well. You were talking about data that belong together should be together but, if I didn’t miss something, I still fail to understand the “why” part of why is sharing data considered bad.
Valid question. The answer is because of this database diagram. Text continues below…
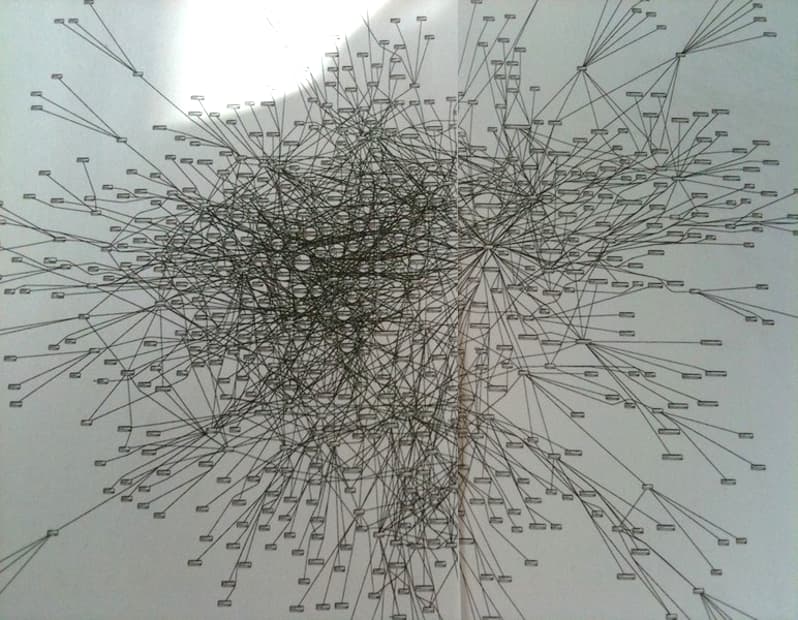
This is a database diagram I was once introduced to and had to work with. And it’s not even all of it, the actual thing was even bigger. The hardest part about a database like this is that there is an insane amount of hidden coupling. This means you can’t just change some code or feature, without potentially breaking a whole bunch of stuff you didn’t even know relied on it. As a result, I’ve been on numerous projects that had a very large test team that ran through hundreds of scenarios to make sure we didn’t break anything. But we still did, because it was hidden coupling and we broke something without knowing. So the test suites were extended with even more tests. Until a point where testing the system took longer than actually developing the feature. Which resulted in automated user interface tests. And then those became so complex, that you’d basically had to write tests for the tests, etc, etc, etc.
There’s no software without coupling at all, because that would mean things wouldn’t work together. But it’s possible to minimize the coupling as much as possible. That’s why Mauro and I created those presentations, to try and minimize the coupling. And it’s why we as Particular Software think you should temporally decouple bigger, logical services using event-driven architecture. And as a result build NServiceBus ![]()
Does that answer your question?
1 Like
Thank you Dennis.
Are you saying that when a service share data with other services, there could be a time when underlying data or something else could change and cause other services that depend on that data break?
When you share data between services, it WILL cause pain. I’ve seen it happen dozens and dozens of times.
The question is, how big are your services? If they’re too small, they’re likely tightly coupled and they have high cohesion and need to work together. If they’re bigger, there shouldn’t be such a need.
2 Likes
Sharing data in itself is not bad, but it is about what data you share. Data comes in different shapes and sizes. Some are more OK to share then others.
@Dennis in his presentations talking about not sharing data and letting others make decisions based on your data. Once you have shared data that others make decisions on, you have a hard time changing your data. You now have external dependencies.
What you want to do is look at the decisions that are made based on the data. Often you can pinpoint who is responsible for that decision, let them be responsible for the data and only share the result of the decision.
Sharing data about behaviors/decisions is usually OK.
Same applies with sharing Id’s. It’s OK to share Id’s.
See for example this discussion:
How not to share data across service boundaries in this scenario? - Architecture & Design - Discussion | Particular Software
It begins with sharing data about employees and their place in the company with other services. Why? Because other services need to make a decision. But if you look closely at the decision it’s not up to other services to make a budget decision. It belong to one service which can share the result of that decision.
1 Like
Could you give an example of what went wrong when data is shared?
I see your point.
I get that data used together should be together but consider this, what if a piece of information from Service 1 is used by more than one services like Service 2, Service 3, etc.? This is what I can’t solve without data sharing or duplicating.
This means you can’t just change some code or feature, without potentially breaking a whole bunch of stuff you didn’t even know relied on it.
If it’s really needed, then the data should probably be inside a single logical service. While coming up with service boundaries, don’t put things together immediately. Don’t name your services. Give them colors. And when you’re really stuck finding where something belongs, bring things together.
I still think this is a very good presentation by Udi explaining a lot of these details.
2 Likes
Thank you Dennis, appreciate it.
1 Like