I had posted this question already on StackOverflow, but I had been advised to post it here too. StackOverflow url: c# - How come sometimes my messages on the NServicebus queue get an infinite DeliveryCount? - Stack Overflow
For some of my NServiceBus integrations, I see that my messages “get stuck”. My queue receives messages from one of my saga’s, and normally everything works fine. The message comes in, its being processed, and then removed from the queue. However, sometimes it just stops removing these messages from the queue. It processes the message (in this case they are being send to a SQL-DB), but then keeps it on the queue, upping the delivery-count by 1. After I notice this, I disable & enable the WebJob that handle my Saga’s (sometimes the DeliveryCounts for individual messages reaches a value of over 3000, even though the default MaxDeliveryCount should be set to 6 according to the documentation). Doing that fixes the problem for awhile, until it show up again at some point.
Some of the WebJobs run on .NetFrameWork 461, these all run fine. The ones that sometimes “stop working” are the ones build on .NetCore 2.1. I’m not implying that this is a problem with the framework, but my guess is that the error might have to with setting up the endpoint (because the EndPoint Configuration is a bit different between these version).
I have already tried to replicate the error by sending 15.000+ messages to the queue, or by disabling the WebJobs and only activating them when the queue is already full. Nothing works, the problem just shows up at pure random. This means that most of the time everything goes fine, up until that one point it decides it wont anymore.
indent preformatted text by 4 spaces
private async Task<EndpointConfiguration> BuildDefaultConfiguration()
{
var environment = this.configuration["Environment"];
var endpointConfiguration = new EndpointConfiguration(this.endpointName);
endpointConfiguration.SendHeartbeatTo($"particular.servicecontrol.{environment}");
endpointConfiguration.SendFailedMessagesTo("error");
endpointConfiguration.AuditProcessedMessagesTo("audit");
var host = Environment.GetEnvironmentVariable("WEBSITE_INSTANCE_ID") ?? Environment.MachineName;
endpointConfiguration
.UniquelyIdentifyRunningInstance()
.UsingNames(environment, host)
.UsingCustomDisplayName(environment);
var metrics = endpointConfiguration.EnableMetrics();
metrics.SendMetricDataToServiceControl($"particular.monitoring.{environment}", TimeSpan.FromSeconds(2));
endpointConfiguration.UseContainer<NinjectBuilder>(customizations =>
{
customizations.ExistingKernel(this.kernel);
});
endpointConfiguration.ApplyCustomConventions();
endpointConfiguration.EnableInstallers();
endpointConfiguration.UseSerialization<NewtonsoftSerializer>();
var connectionString = this.configuration["ConnectionStrings:ServiceBus"];
var transportExtensions = endpointConfiguration.UseTransport<AzureServiceBusTransport>();
transportExtensions.ConnectionString(connectionString);
transportExtensions.UseWebSockets();
transportExtensions.PrefetchCount(1);
// license
var cloudStorageAccount = CloudStorageAccount.Parse(this.configuration["ConnectionStrings:Storage"]);
var cloudBlobClient = cloudStorageAccount.CreateCloudBlobClient();
var cloudBlobContainer = cloudBlobClient.GetContainerReference("configurations");
await cloudBlobContainer.CreateIfNotExistsAsync().ConfigureAwait(false);
var blockBlobReference = cloudBlobContainer.GetBlockBlobReference("license.xml");
endpointConfiguration.License(await blockBlobReference.DownloadTextAsync().ConfigureAwait(false));
endpointConfiguration.DefineCriticalErrorAction(async context =>
{
try
{
await context.Stop().ConfigureAwait(false);
}
finally
{
Environment.FailFast($"Critical error shutting down:'{context.Error}'.", context.Exception);
}
});
return endpointConfiguration;
}
I have included the function that sets up the EndPointConfiguration. I expect I’m missing something here that is causing the error, but I have no idea what it is. To clarivy: I do not actually receive an error. I just notice that messages are being processed, but not being removed from the queue.
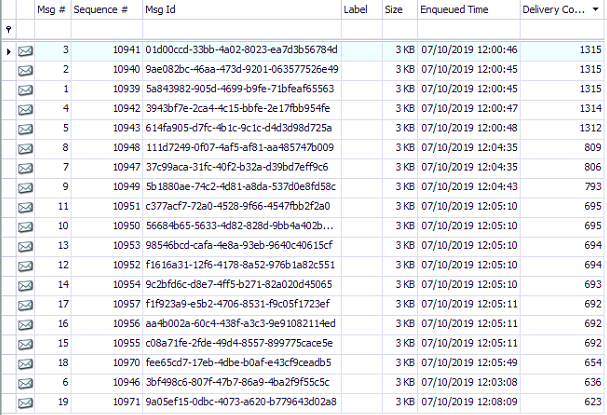
Edit:
I have added a screenshot from the queue through QueueExplorer, to visualize the problem. There where around 300 messages on the queue before I took the screenshot. Those where all being blocked by the messages you can see in this picture. A simple restart of the webjob that contains the handlers for these messages fixes the problem, until it goes wrong again.