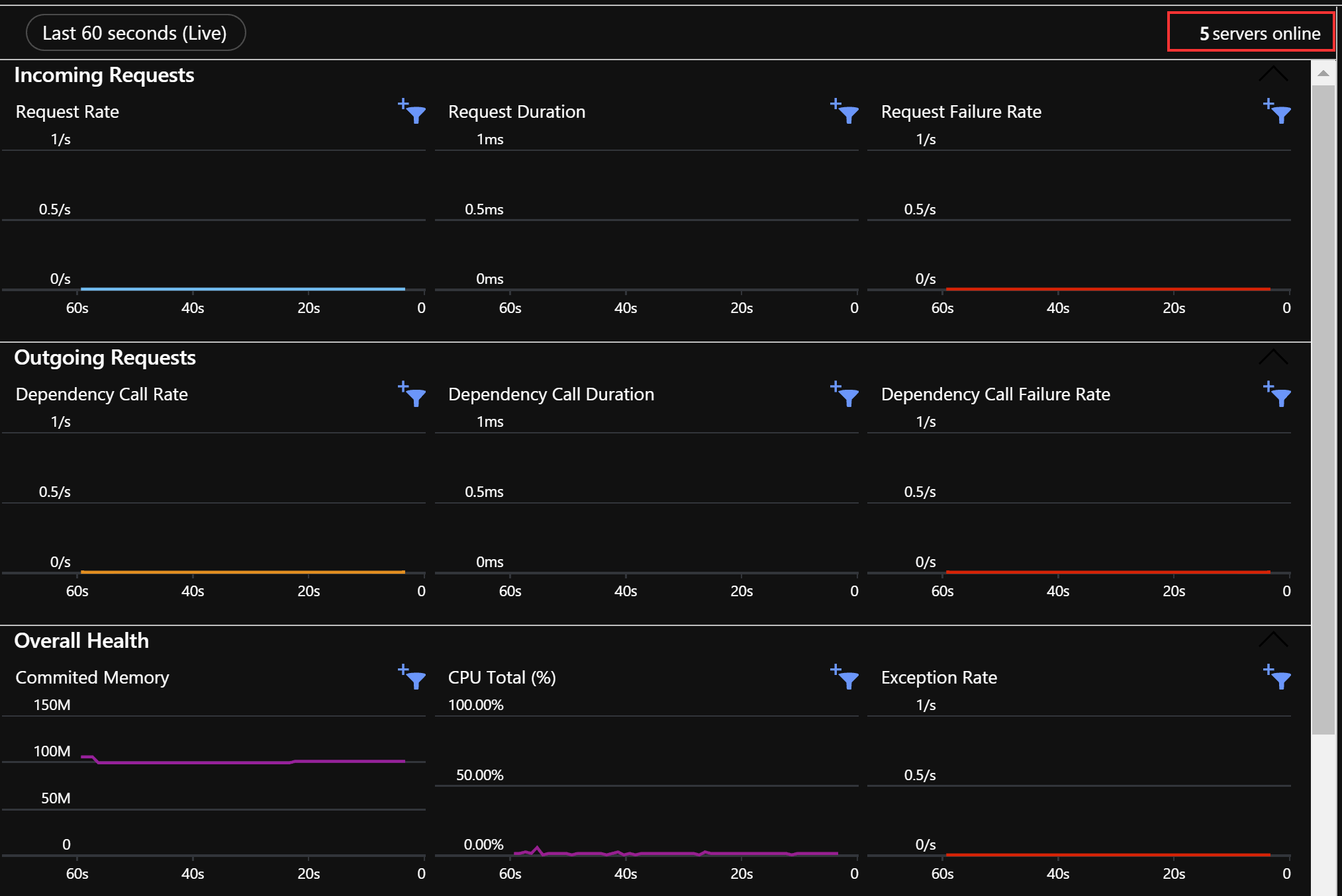
Maybe just a “FYI” as this is not caused by NServiceBus but when hosting an NServiceBus Endpoint with Azure Functions with a consumption plan (perhaps premium as well) scheduled messages on the Queue will cause the scale controller to start creating more and more instances of the app, even if it’s under no load.
This will happen if you have a lot of Saga timeouts or other delayed messages as all of these translates to a scheduled message on the Azure Service Bus queue. Apparently, the scale controller can’t distinguish between active or scheduled/deferred messages so it sees a message and the time of arrival (which might be some time ago) but not that it should be processed later, so it will start spinning up new instances.
There is an open issue: ServiceBus Triggered Functions Overprovisioning · Issue #715 · Azure/Azure-Functions · GitHub but it’s been open since 2018…
If you would like to reproduce this without any involvement of NServiceBus, you can add these three functions to a function app on a consumption plan and watch the server count in like Application Insight:
[FunctionName("MyTrigger")]
public static async Task QueueTrigger([ServiceBusTrigger("debug", Connection = "AzureServiceBus")]
string myQueueItem,
ILogger log)
{
log.LogInformation($"Message: {myQueueItem}");
}
[FunctionName("SendImmediate")]
public static async Task<IActionResult> SendImmediate(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = null)]
HttpRequest req,
[ServiceBus("debug", EntityType.Queue, Connection = "AzureServiceBus")]
IAsyncCollector<Message> messages,
ILogger log)
{
log.LogInformation("Sending message immediately");
var bytes = Encoding.UTF8.GetBytes("Immediate message");
var message = new Message(bytes);
await messages.AddAsync(message);
return new OkResult();
}
[FunctionName("SendScheduled")]
public static async Task<IActionResult> SendScheduled(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = null)]
HttpRequest req,
[ServiceBus("debug", EntityType.Queue, Connection = "AzureServiceBus")]
IAsyncCollector<Message> messages,
ILogger log)
{
var seconds = 60;
log.LogInformation($"Sending message scheduled in {seconds} seconds");
var bytes = Encoding.UTF8.GetBytes("Scheduled message");
var message = new Message(bytes)
{
ScheduledEnqueueTimeUtc = DateTime.UtcNow.AddSeconds(seconds)
};
await messages.AddAsync(message);
return new OkResult();
}
Just post to the endpoints, especially the SendScheduled one… After about a minute or so new instances of the app will be created if your function app is hosted on a consumption plan.
For us, this simulated the behavior with our Sagas and their Saga Timeouts which caused the host to start scaling without actually needing it…
So, Azure Service Bus does indeed have native support for scheduled messages, but it might have an unintended side effect of over-scaling if you have a Function App on a Consumption plan… Perhaps something for the documentation? Unless I’m completely wrong about this ![]()
//J