Hi All,
I was wondering if ServiceControl 1.47.2 supports partitioned Azure Service Bus queues for the audit queue? I keep running out of space on my audit queue (5 gb non-partitioned). Perhaps it means trouble else where but changing to a partitioned queue would give me a lot more space. Bonus points if I can not delete my current service control instance in the process of switching.
Thanks,
Nate
Hi Nate,
With Partitioned queues it’s not enough to have your audit queue partitioned. Endpoints input queues and error queue would need to be partitioned as well. That means any queue that was created as non-partitioned would need to be deleted and re-created as partitioned. If you have messages in flight, you’d have to drain them all. That would include delayed messages or any saga timeouts. Is that something you’d think you could do with your system in production?
Additional question I have is what’s the message load in your system that audit queue of 1GB ends up filled? Is your SC not able to keep up with the load on the audit queue?
Thank you,
Sean
1 Like
Good to know. I am definitely doing it wrong. Some of our queues are partitioned if they are high volume and the rest are not, including the error and audit queues. I didn’t realize it was an either/or thing, is there documentation on this point that I missed?
Likely what I will have to do is create a new production Azure Service Bus and run in parallel for a day or two while delayed messages are processed.
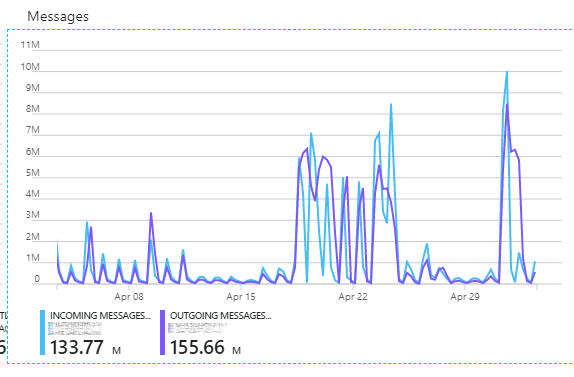
We have around a million messages per day with peaks around 8 million. (per Azure’s report)
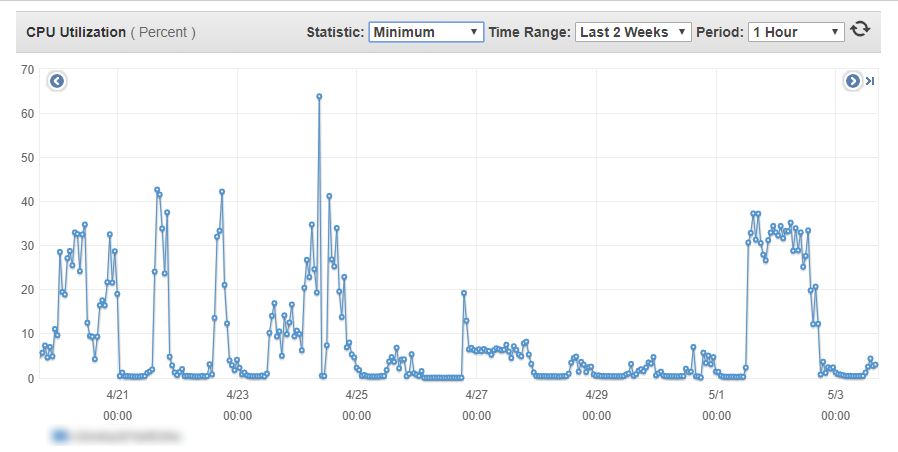
This is the cpu utilization of the server i have Service Control running on for the last two weeks. It doesn’t look too over worked but welcome feedback. AWS m4.xlarge (4 2.3 GHz Intel Xeon vCPU, 16GB memory)
We’ve been migrating to using NServiceBus over the last year but this last month we enabled the last big piece of it. We currently have about 15 service bus hosts.
How big are your messages? If 1GB queue is getting filled up, is your SC deployed to a VM that is strong enough to process at the rate you’re receiving?
As a potential workaround, you could configure your audit queue to forward messages to a new queue, let’s call it audits-partitioned that would be partitioned. That way, you could create it as a 5GB partitioned queue, which is 80GB behind the scenes and not worry about the size.
I think you must be right about the SC being swamped. Once it finished processing the queue, it has been able to keep up. Could be that the service stopped, the queue got full, and then we started it up again. To answer your question, the server is running in AWS EC2. I didn’t request a dedicated box, so it probably is a VM.
I’ll look in to your suggestion of forwarding. I will likely just recreate my environments with partitioned queues.
Thanks for your time!
That’s a possible scenario. You could look in the logs to see what was happening.
You’re welcome.
Hey Nate,
Sean and I discussed this briefly and it sounds like he was assuming that by partitioning you meant partitioning for a business-specific reason, like sharding, where the incoming/outgoing partitions must match, or something like that.
If you’re using native, you definitely have to worry about this. Using atomic sends/receives you’ll get an exception if you try to engage two partitions in the transaction. But NServiceBus and the ASB transport will echo the incoming message’s partition key into the outgoing message when you’re doing atomic sends/receives, so no problems.
We ran a sample both ways to ensure this was the case.
By the way I hope you never have to deal with a queue size of 5GB+ ever again. 
-David
1 Like