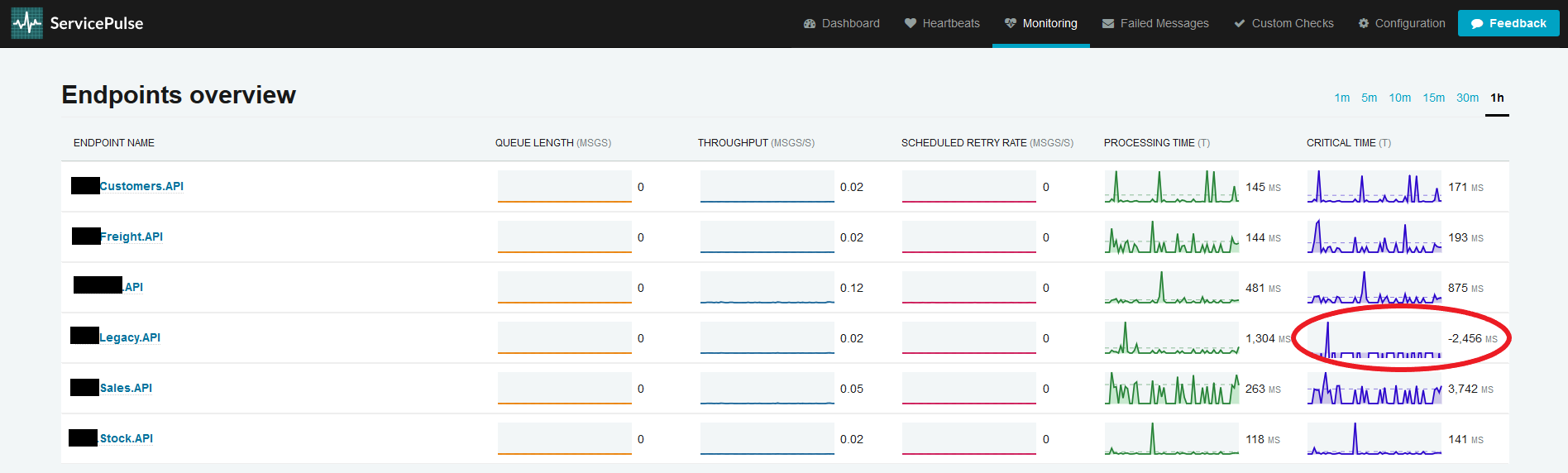
Our stats in ServicePulse are showing negative stats on Critical Timings. I have tried to find out what is causing this - since our other endspoints do not show this kind of behaviour.
This specific endpoint is running on a on-premise windows machine (self-hosted dotnet core).
This issue is occuring for our endpoint in ACC adn PROD - for the endpoint in TST this is not the case.
The other endpoints you see in the screenshot are running in Kubernetes. And we use RabbitMq as transport.
Thanks for letting us know. I’ve reached out the team to report this.
Is there anything that’s unique about these endpoints? Are they deployed on a different server compared to the ones that report correctly that can exhibit the time sync issues like Ramon suggested?
What’s the version of ServicePulse and ServiceControl monitoring?
We’ll get back to you if we need more details on this or if we have any updates.
Yes, this specific endpoint is running on a Windows host. While the others are hosted in Kubernetes. So the time difference could well be an issue, but what should be a correct fix for this? How could we synchronize these?
the most common approach to time synchronization is to configure NTP (or Time Synchronization on Windows). This is done at the operating system level (Kubernetes node).
Have configured the NTP on the machine on which the Legacy endpoint was running and this seems to be the fix! Will monitor some more the upcoming days, but this looks promissing.