Hi Andre
A single ServicePulse instance can be used to connect to multiple ServiceControl instances by switching the connection.
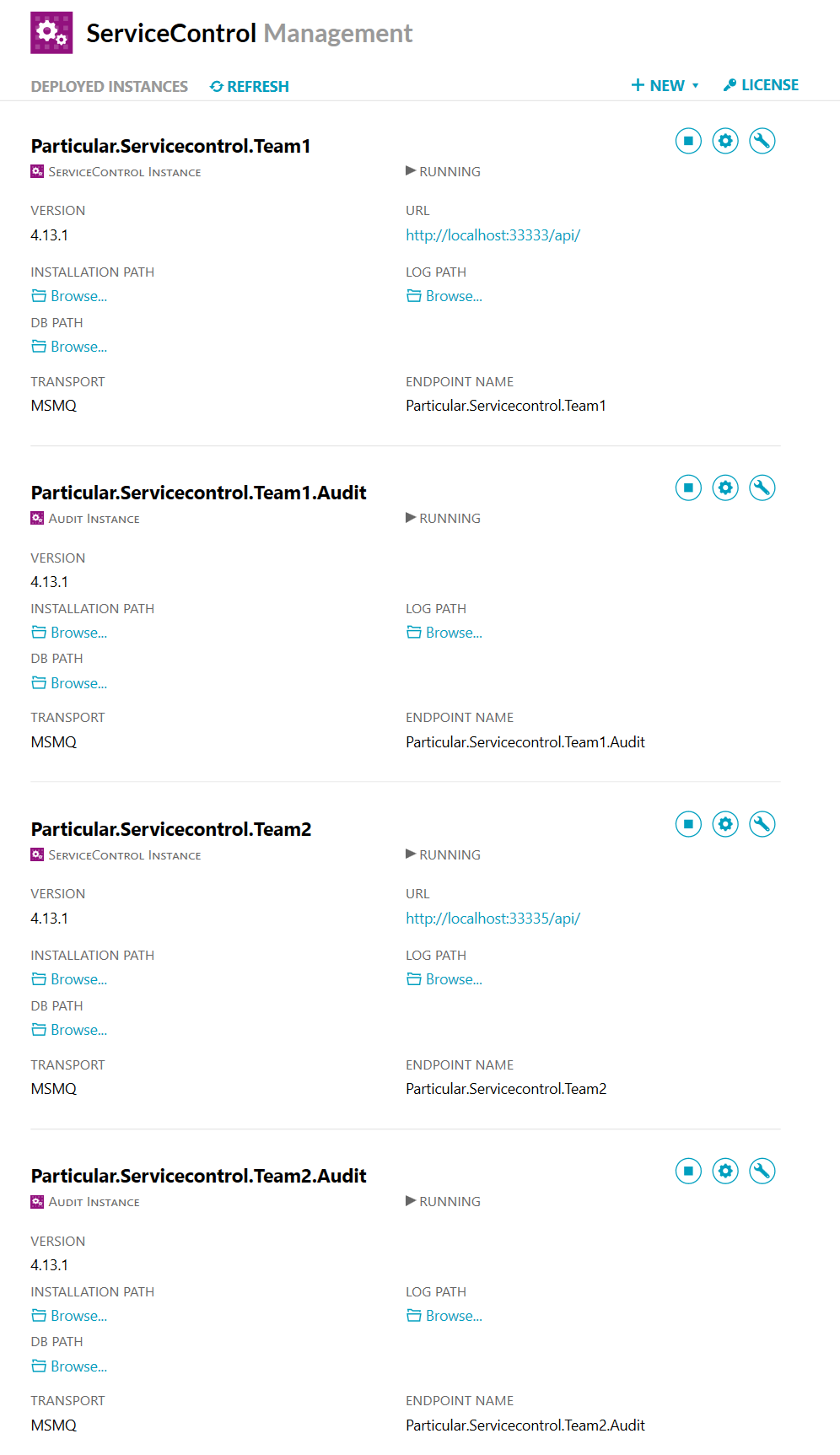
Here is a setting of two teams where each team has their own dedicated error and audit queue
The only thing I made sure during installation was to set appropriate service names as well as configuring for each installation the queue configuration of the instance accordingly
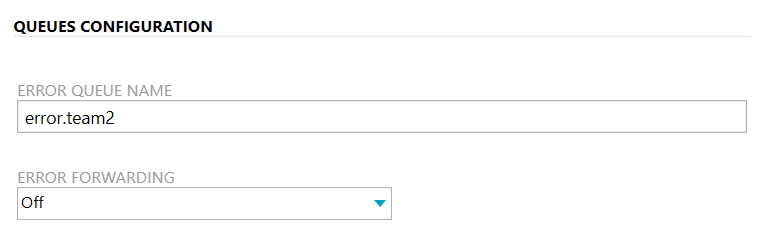
The error queue configuration of team 1
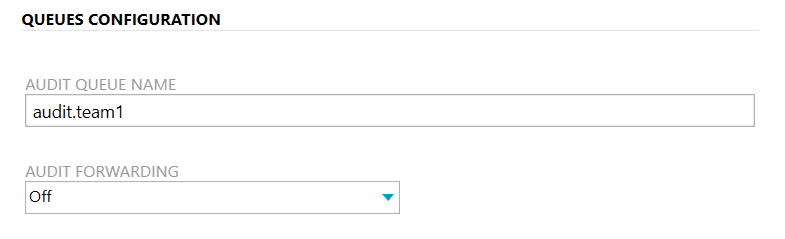
The audit queue configuration of team 1
If you want to have a centralized audit queue instance you but dedicated error instances only you need to follow the remote instance guidance and do part of the work either manually or using the PowerShell scripts.
A quick example of how this can be achieved manually when setting up the team 1 instance I configure the queue configuration as before
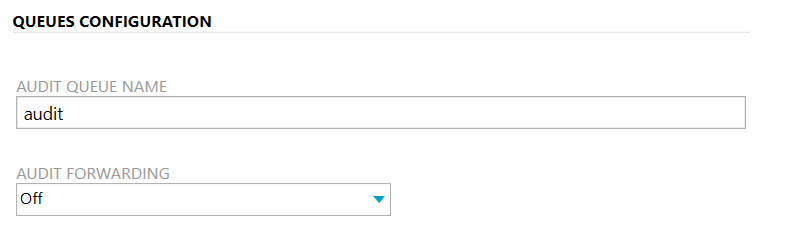
the audit instance becomes a clear name that indicates that is the centralized one
Queue config points to the centralized audit queue
Then I setup the Team 2 instances
The audit instance of Team 2 is just temporary
so add any arbitrary queue name (we are going to delete that instance soon). Normally you could add !disable to the queue configuration but it seems there is a current regression that we have to address first.
Once installed removed the unnecessary Team2 audit instance. Stop the Team2 Error instance, edit the config and adjust the remote instance location to the location of the centralized audit queue, in my example it was
<add key="ServiceControl/RemoteInstances" value="[{"api_uri":"http://localhost:44444/api/"}]" />
Restart.
To your other questions
Any documentation that describes this setup scenario?
Unfortunately this is an uncommon scenario that we don’t have documentation for. It is basically a mixture of regular installation with some remote instance modifications.
How to designate a service control instance towards a specific bus and specific error and audit queue?
That is just a matter of setting up the right connection string as well as filling in the correct queue configuration as pointed out.
All the service control instances can be configured on the same machine (VM), right?
They can yes as long as the machine takes into account the hardware requirements per instance. Also be aware that having a shared instance ingestion speed of several instances might be influenced due to “noisy neighbour” effects.
I hope that helps
Regards
Daniel