Hi
We’ve been able to identify a likely cause of the issue. In line 57 in the ApplyDefaultConfiguration method there is a call to UseTransport. While it looks innocent, it seems to cause the problem as I was able to reproduce it using our minimal functions sample
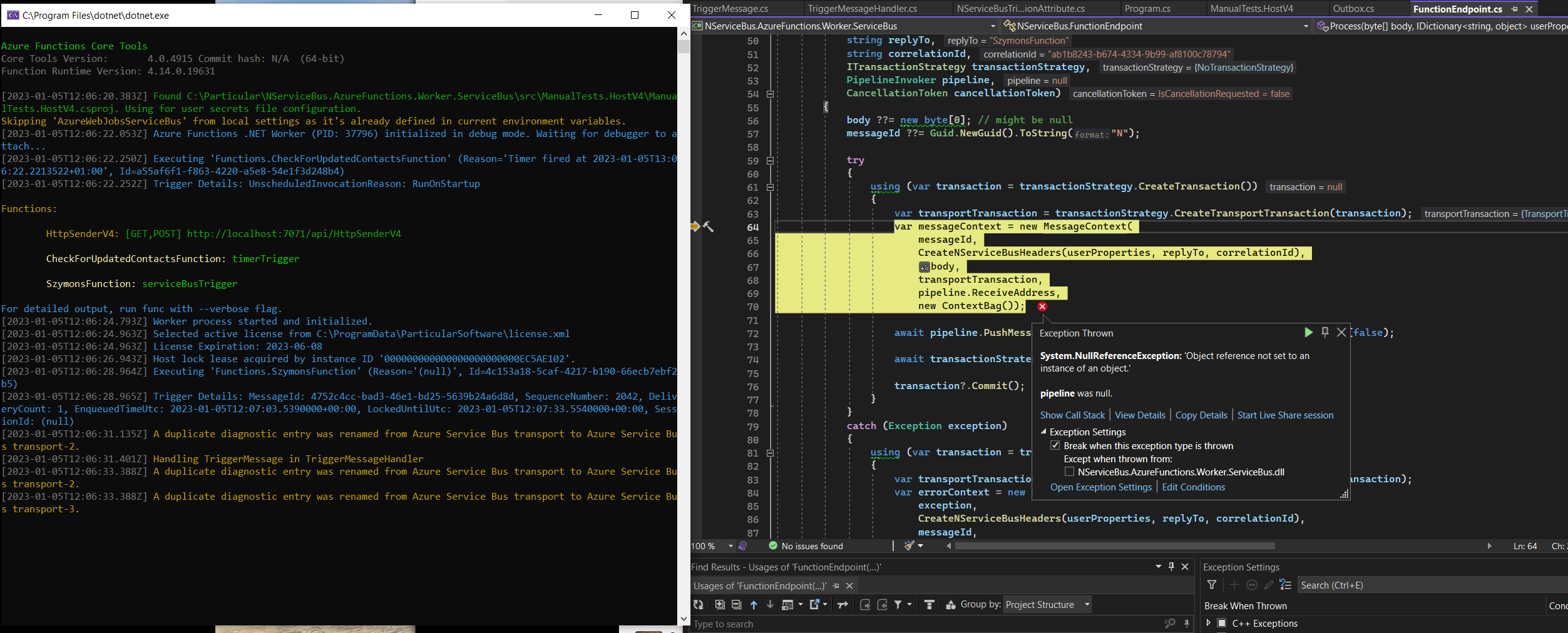
The root cause is the fact that in order for the functions to work, the functions setup replaces the transport you configure with a shim serverless transport that does not pump messages (like regular transports do) but offers API so that we can pass the message that we get from the functions host via the trigger.
At the point of time when line 57 is executed, the transport of NServiceBus is already set to that shim and line 57 replaces it with a regular transport. This causes the shim to be not started so the messages passed from the host are not being processed (resulting in lock renewal problems) while the process pumps messages like a regular (non-serverless) endpoint.
We are fairly sure that removing the code in line 57 should fix the issue. We are also actively working on reviewing the APIs of our serverless packages (both for Functions and for AWS) to remove glitches such us this one.
Sorry for the problems and thank you for your patience and all the information you shared with us. Without it we would not be able to identify the issue.
Sz